
Friday late afternoon, the end of the working day, a message about a customer reaching out because of many vMotions in vCenter that are not able to complete. More than 275 emails from vCenter with errors. In this blog, we take a deeper dive and find out why it was not possible to successfully perform a vMotion.
Table of Contents
The infrastructure
This situation happened in a VMware Hyper-Converged Infrastructure (HCI) that has a total of ten ESXi vSAN nodes version 7.0U3. There are two main locations (A and B) for hosting services, and there is a stretched vSAN datastore. Also, there is a third location (C) that hosts the required vSAN Witness. I myself like to think in images, and that is why the High-Level Design of the infrastructure is shown below.

The error
The issue is quite clear: no vMotions are possible at this point. Every time a vMotion is scheduled -it doesn’t matter whether manual or via DRS- it comes back with an error message as shown below. The first thing to notice is that there are roughly 200 VMs hosted on the infrastructure, and they are causing many errors as DRS is trying to balance the cluster. The first step in troubleshooting was to stop VMware from polluting the logs and set DRS on the cluster to manual. After manually trying to vMotion a VM, it showed an error that is shown below and it states: “Failed to migrate the virtual machine for reasons described in the event message”. Well, that’s not that much information to work from, so let’s check the event message: “[…] can occur if vMotions IPs are not configured, the source and destination host are not accessible and so on. […]”. Also not that informative, thanks vCenter!
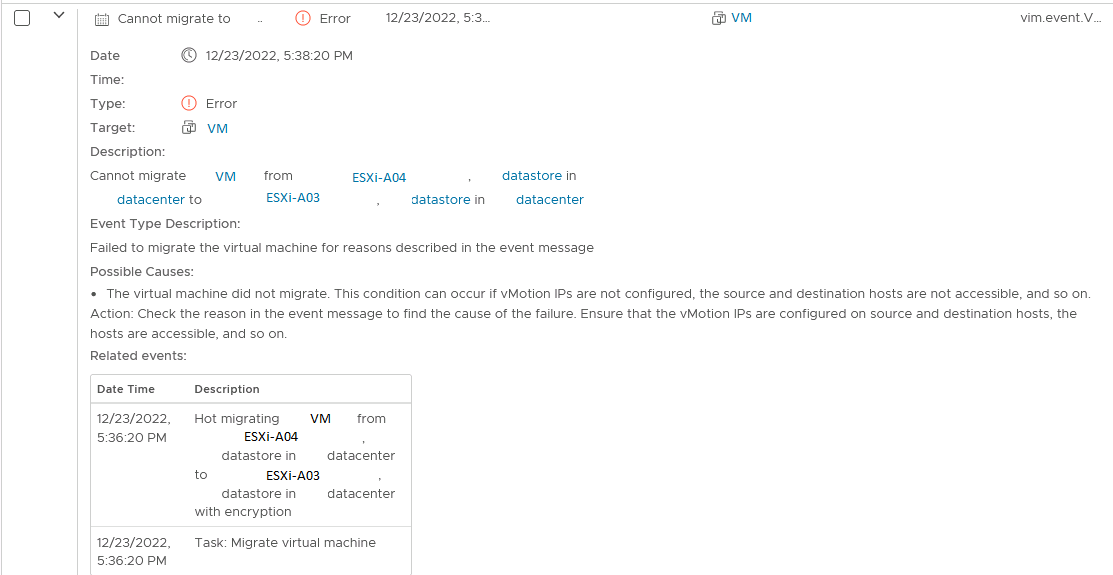
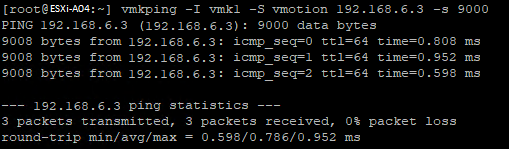
I don’t often get the feeling the error messages in VMware vCenter are helpful in finding any issues, and this one was no different. The infrastructure has a dedicated -non-routed- VLAN for vMotions, which has worked up till this point. No changes should have been made on the vMotion VLAN, but just to be sure, let’s exclude the vMotion network anyway. After turning on SSH on an ESXi node and using vmkping to test the vMotion network connectivity, it was at least clear that the vMotion network was working as expected.
The search
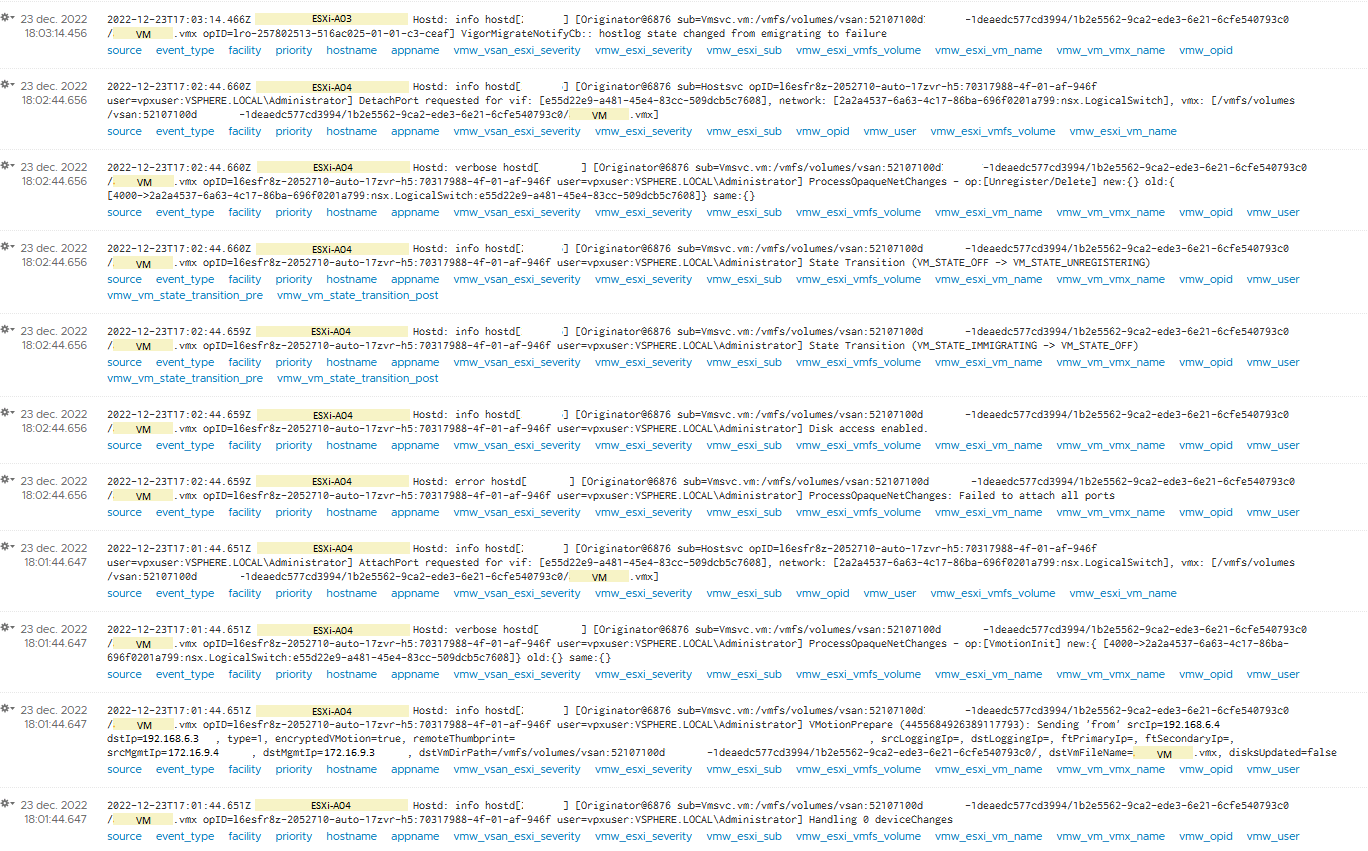
Luckily, there is a VMware vRealize Log Insight (vRLI) instance available that collects the syslog messages from the ESXi hosts. Hopefully, vRLI will be more helpful than vCenter on this quest to resolve the issue. With DRS set to manual, I tried to migrate a VM to another ESXi node and checked the logs with the corresponding timestamp. The screenshot below shows that syslog output and for me the message at 18:02:44.656 that states “[…] ProcessOpaquieNetChanges: Failed to attach all ports” stands out.
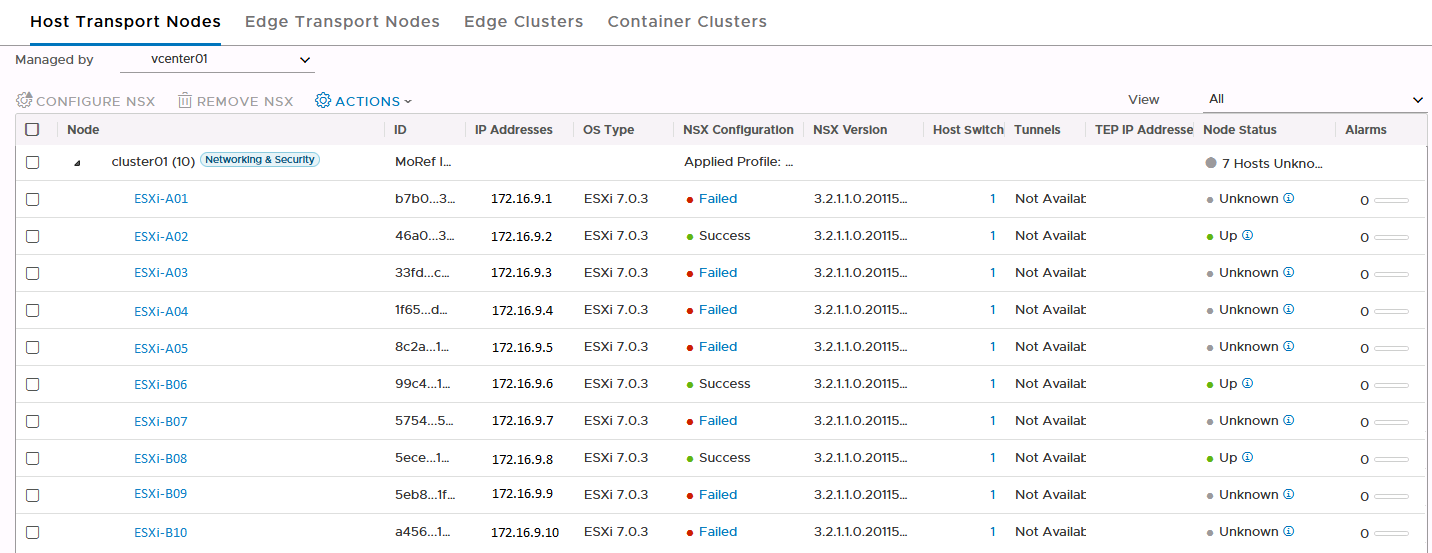
In this infrastructure, VMware NSX is being used for distributed firewalling. This error led me to believe the issue might be with NSX, while performing a vMotion, a change is required on the data plane of the network because the traffic now needs to be tunneled to another ESXi node. With that information, it was time to have a look at the NSX manager UI. The first thing I noticed was that there are absolutely no alarms popping up while logging in. This I found so interesting that I even contacted a colleague in most infrastructures I log in, there are usually at least a few alarms welcoming me. After that, I continued, and I came to the screen with the Host Transport Nodes. Here I saw that many nodes that have issues with communication to the control plane. This was easily visible because only three out of ten nodes had a green status with meant that they were able to successfully apply the NSX configuration.
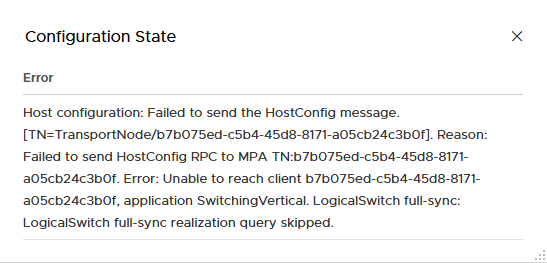
Luckily, the NSX UI offers the possibility to try to resolve the failed configuration state. That was the first thing to try of course and I hope for a more informative message than vCenter. Sadly the error didn’t give that much information either “[…] Failed to send HostConfig RPC to MPA […]” and “Unable to reach client […] full-sync realization query skipped […]”.
So, back to vRLI to see if there is a more explaining error to find, after filtering on NSX, the graph showed considerably more log entries from roughly 14.15 onwards. The log shown below popped out to me. “[…] Couldn’t connect to tcp://127.0.0.1:9100 (error: 111-Connection refused)”

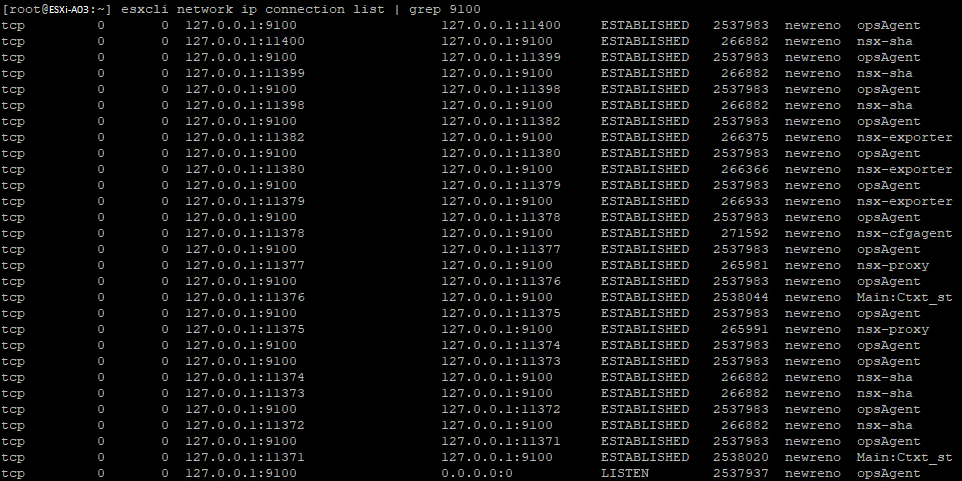
That is very interesting, which service uses TCP/9100? I know some old HP JetDirect printers used to use that port, but nothing for NSX comes to mind. So, off to ports.vmware.com to verify! A quick search within the NSX products shows that there is no match found on TCP port 9100. On a failed ESXi node (A03), there is no service listening on port 9100. However, on the default ports -TCP/1234 and TCP/1235- there are NSX services running for messaging between managers and nodes.

Afterwards, I wanted to verify what communication would use TCP/9100 and also find what services are using that port. It turns out, a lot of very important services -e.g., nsx-opsAgent, nsx-cfgagemt, nsx-sha, nsx-exporter- are using this port. The reason the port is not mentioned on port.vmware.com is that it only listens on localhost (127.0.0.1) but still, apparently, it’s very critical for NSX to function.
The issue
Now, with the differences between a working ESXi node and a not working node clear, the issue seems to be with the NSX-opsAgent on the ESXi nodes. When VMware NSX is used, communication between the ESXi nodes and the NSX Managers is of utmost importance. A vMotion can only be successful when the NSX control plane is able to tell other nodes on which ESXi node the VM resides.
At this point I wanted to test a hypothesis, could we still vMotion to an ESXi node that does have contact with the NSX manager? I moved a VM, and apparently, it was able to complete successfully because that ESXi node was able to communicate with the NSX manager! That’s great news, now we can empty out a broken ESXi node, and we can dive deeper into the issue.
With the ESXi node in maintenance mode, the first step in trying to resolve the issue was to restart the nsx-opsAgent service. The output is shown below.
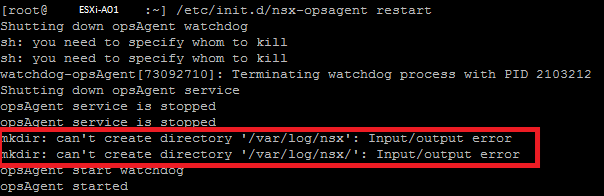
I outlined two output rules here that are very important, “mkdir: can’t create directory ‘var/log/nsx’: Input/output error”. They are interesting because, why is the NSX process not able to create this log folder? A quick check with ‘df -h’ shows that the scratch partition is a whooping 0 bytes big. Well, that is definitively not right, it should show some hundred gigabyte. The Dell PowerEdge servers used in this infrastructure have a 32 GB SD card where VMware ESXi is installed. Following VMware’s best practice, the scratch partition was moved off the SD card and on to an NFS location. Because of the monthly Windows updates, this NFS location was temporarily not available during the day, but all should function now. However, the ESXi node seems to be convinced that the NFS location is still inaccessible, making it impossible for NSX to write a log towards and thus for the nsx-opsAgent to start probably. This is all strange since the last messages of the restart clearly stated “opsAgent started”.

![]()
The solution
Now comes the hard part, remounting the NFS location, it’s tricky to do a remount of an NFS location on an ESXi node. Normally, one would unmount the NFS in vCenter and then mount it again. However, since this NFS mount is configured as the scratch partition, an error pops up that the location is still in use and therefore cannot be unmounted. Now with the ESXi node in maintenance mode, it was better to perform a complete reboot of the node which completely resolved the issues. After that, the scratch partition was mounted successfully and the NSX-opsAgent started. Also, the ESXi node now had a green status in NSX and vMotions were possible again.
The cause
In the end, it turned out that the NFS server was rebooted to accommodate the installation of updates. This is done on a monthly basis, but only now caused issues. For the past months, no issues had been observed, so what changed? Well, the updates applied to the Windows NFS server caused something in the NFS service to change and not accept clients back that easily, since ESXi doesn’t retry to connect the NFS mount was deemed inaccessible. Best would be to stop using SD cards in the servers and move to BOSS cards, preventing this whole situation, or to just not reboot/restart the NFS server.

Can also be caused when a host is upgraded and the host license is not applied.